2023年の振り返り~telnetdは落としましたか?~
早いものでまた年末の一年の振り返りエントリーです。
旅行などがまた戻ってきた一年でしたが私は足の調子もあって移動の少ないままでした。
今年も印象的だったものをあげていきます。
・SNS/microblog
Xからの移行先の検討に長い時間を費やしてムダにアカウントを増やした一年でした。
開くのが楽しみなのはタイッツーなのですがTLにテックな情報はうっすいので、移行先はBlueskyかなあというお気持ちです。
懸念はビジネス持続性と、10数年前のツイッタ同様やたらクライアントばかりが開発されている点です。その道はもういいのでは...という思いがよぎります
残念ながら終了してしまいましたがT2/Pebbleは幸せな空間でした。日本ユーザーがやたら上げる食事の写真が欧州方面のユーザーに人気があり、私は欧州ユーザーが上げる街角の風景がとても好きでした。撮影したユーザーさんの生活や温かみが感じられるのは緩いSNSならではの特長だったと思います。
T2/Pebbleの一部ユーザーはマストドンインスタンスへ転生しています。
pebble.social
・Loose control
去年で言う甲賀忍法帖枠です。
Loose controlはSKE48 チームEの新公演「声出していこーぜ」の中の一曲です。
斉藤真木子のパフォーマンスが圧巻でした。滞空時間あふれるいつもの動きではなく低めの姿勢が多い振り付けですが目線や重心からさえもストーリーを組み立てて見せてくれます。ぜひ生で観てみたいステージングでした。
・テック方面
生成AI系はお遊びでしか使っていません。変数名がイギリススペルな提案を受けた時に余計な確認とストレスで効率が落ちたので一旦見送りました。
登壇も今年はできませんでした。来年こそ
成果共有ではなく疑問ぶっつけなネタが2つくすぶっています。
一つ目は「2019年までに始めなかった人にとっての現在のAnsibleの高い障壁っぷり」
二つ目は「ゆとりのある復旧計画を生み出してしまう"レジリエンスエンジニアリングらしきもの"への疑問」
これもどこかで疑問ふっかけLTしたいんですがstabilityは障害への理解を拡げる方向に行きがちでresilienceはシステムへの理解を深める方向の気がするんですよね
— S.Komichevsen Matsuk (@w4yh) December 18, 2023
で、最近ITシステムの一部でresilienceっぽく話されてるのがほとんどstability寄りだったり..
k8s方面かSRE方面で話してみたいです < RT
さらに言語化して整理したいと思います。
kondateがparallel 1.23.0でエラーになる
自分用の備忘メモです
長年Kondateを使っています。itamaeとServerspecを良い感じにセットで使えるようにしてくる便利!ツールです。
github.com
先日新しく実行環境を作ろうとしたところエラーとなりました。
$ kondate init . /home/hoge/.anyenv/envs/rbenv/versions/3.1.4/lib/ruby/3.1.0/rubygems/core_ext/kernel_require.rb>:85:in `require': cannot load such file -- parallel/processor_count (LoadError)
調査にだいぶ手間取ったのですが、parallelのファイル構成が変わっていました。
$ ls ~/.anyenv/envs/rbenv/versions/3.1.4/lib/ruby/gems/3.1.0/gems/parallel-1.22.1/lib/parallel processor_count.rb version.rb $ ls ~/.anyenv/envs/rbenv/versions/3.1.4/lib/ruby/gems/3.1.0/gems/parallel-1.23.0/lib/parallel version.rb
processor_countの呼び出しをpatallel本体からに変えて回れば良いのでしょうが、
ひとまずparallelのバージョンを下げて解消しました。
Gemfile gem 'parallel', '1.22.1'
または
$ gem install parallel -v "1.22.1"
めでたしめでたし(先送り?)
2022年印象的だったこと
一年の振り返りエントリーです。今年はアウトプットも少なかったですが読書量も少なかったので、ぼんやりと"印象的だったこと"のくくりで書きます。
甲賀忍法帖
今年一番の衝撃はこれですね。
/ #チャンピオン の歌声を
— NHK山口放送局 (@nhk_Yamaguchi) 2022年8月29日
もう一度!
\
山口県 #周南市 で開催された #のど自慢 から、松山唯さんの #甲賀忍法帖 をお届けします。 #NHKプラス でも見逃し配信中!
全18組の歌声を
ぜひお楽しみください♪
👇https://t.co/t5WfGKYrmt pic.twitter.com/YUiKG9ePZE
久々に曲を聴いて興奮したのもありますが、歌の上手さから立ち居振る舞いからステージングが完璧すぎて感動しました。凄かった
Web3/Web2.0
荒れましたねー
新しい物は既存の物の欠点を補うまたは改善するという面を持つものですが、既存の物をあまり攻撃しすぎてはいけませんね。
インフラエンジニアは知っているはずです、BIND9の欠点を散々なじってきた人たちがBIND10からBIND9に戻る宣言をしてしまうのを見た時のあの感情を
ZOHO SOHO
これも衝撃的でした。
過去のZoholics! Japanなどのユーザーイベントに於いて「ZOHOの語源はSOHOである。○か×か」というクイズが何度か出されました。
従来答えは×で、SOHOは当時たまたま持ってたドメイン名を使ったという説明だったのですが
今年のZOHOLICS JAPANにおいてCEOのSridharさんから「ZOHOの語源はSOHO」という言及がありました。ナ、ナンダッテー
個人的な推測ですが、「たまたま持ってたZOHOというドメイン名はSOHOをもじって取った」というさらに一段階踏み込んだ事実が明かされたのかなと思います、うん。
腱鞘炎
去年は帯状疱疹に苦しみましたが、今年は腱鞘炎に苦しみました。一番ヒドいときは上半身がろくに動かせず握力が12kgまで落ちていました。
リハビリしたりストレッチしたり姿勢に気を付けたりと難儀ですが職業病的な面もあるのでうまくなだめて付き合っていきたいです。
まとめ
今年も健康を維持できずご時世的にも難儀な一年でした。
実務の方では地に足の付いた活動ができてきたので、来年はアウトプットを増やしていきたいです。まず年末年始はようやく買ったISUCON本を読みます。
それでは2022年の御礼と2023年へのご挨拶に代えて
Zulipはいいぞ
tl;dr
Slackとここが違って良いです
・スレッドに名前を付けて個別に選択できる
・"すべてのメッセージ"画面でひとつのTLとして読める
チャット系ツールとしてZulipを長いこと使っています。「Zulipはいいぞ」と一言つぶやいてばかりなのも生産的ではないので一度まとめておきます。
概要
Zulipはひとことで言うとSlack競合のチャットツールです。
github.com
zulip.com
オープンソースでGitHub上に公開されていてセルフホストが可能です。またSaaSサービスも提供されています。
元々はステルス段階のスタートアップだったのををDropboxが買収し、オープンソース公開したりスピンオフで再分離したりを経て現在はKandra Labsを中心に開発とサービスが行われています。
お気に入りのツールなのであらためてご紹介いたします。
昔話
私は2016年にそれまで使っていたLet's Chatからの乗り換えで使い始めました。
当時オープンソースのチャットツールではZulipの他にMattermost、Rocket.Chatを検討候補としました。
Zulipにしたのはコミュニティの反応の良さでした。
当時「日本語検索ができないけど何か設定漏れてるかしら?」とぼんやりしたイシューを投げました。
「Postgresのdictionaryファイル差し替えないといけないね」とすぐにお返事いただき、「マジか..Postgres分かんねー..」とメソメソしていました。
ちょうどその頃PGroongaの勉強会があったので、「こんなやりとりしてたけどPostgres分からなすぎるので学びに行きますっ」と申し込んだのですが、なんと
github.com
PGroonga作者様が全文検索機能をZulipに実装してくださるというミラクル!うおおおーすげえー @ktou さんかっけー
というわけでZulipは /etc/zulip/settings.py に USING_PGROONGA = True を設定して manage.py を実行するだけでPGroonga検索が有効になります。
zulip.readthedocs.io
Zulipのここが良い
(1)全文検索が強い
前述の通りです
(2)Home TL画面がある
参加しているすべてのストリーム(Slackで言うチャンネル)を時系列に表示した"すべてのメッセージ"画面があります。
新しい物が下に表示されるという点を除けば、ツイ廃のみなさまがいつも見ている画面と同じ感じです。各チャンネルを選択して回るのが面倒な方にオススメです。
(3)スレッドがメールのように見やすい
各ストリームの中でさらにもう一階層"トピック"という分類ができます。スレッドに名前を付けて管理できます。
サイドバーにも各ストリームの下にトピック一覧が表示されていて選択表示できます。
Slackのスレッド表示が苦手な方にはイチオシの機能です。
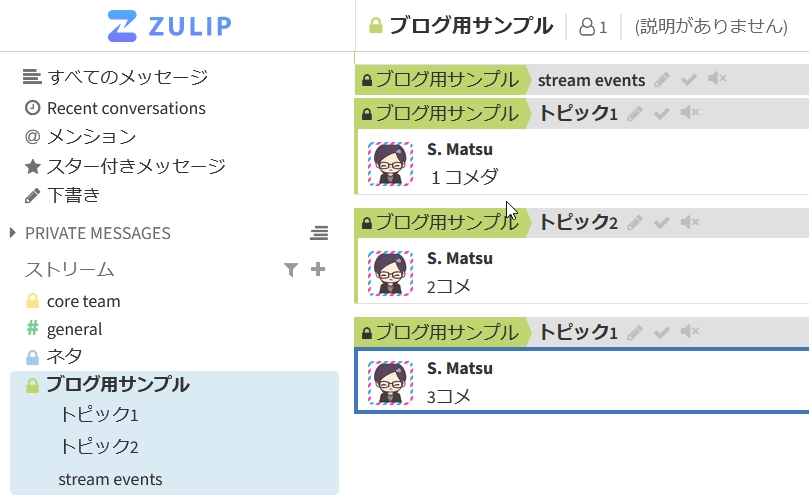
"トピック1"を選択した状態

(4)自動リンクが地味に便利
特定のパターンを検知して自動的にリンクに変換する機能があります。
設定画面で表示されている下記画像の例では #の後に数字を書くとGitHubのIssueにリンクされます。
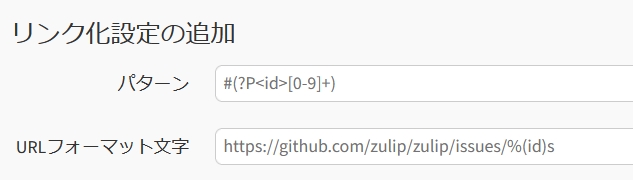
チケット番号やCVE番号に用いていますがとても便利です。
(5)Botが作りやすい
HubotのZulipコネクタがあるのでHubotでBot作成ができます。
また、zulip_botsという独自のフレームワークもありお手軽にbotを生み出せます。
https://zulip.com/api/running-bots
(6)Botだけでなく多様な連携
https://zulip.com/integrations/
これはイマドキ当然ですかね。様々なツールと連携できます。私はHubot以外にメールとRedmineとZabbix、GoCDなどと連携させたことがあります。
OSSコミュニティに便利な機能
Rust言語のコミュニティがZulipをヘビーに使用されていて参考になります。
https://rust-lang.zulipchat.com/
(日本語コミュニティ)
https://rust-lang-jp.zulipchat.com/
OSSコミュニティに向いている機能として以下が挙げられます。一言で言うとDiscourseっぽいことができます。
・ストリーム毎にパブリック公開設定が可能
https://zulip.com/help/public-access-option
SlackなどのWalled Gardenな環境は検索からアクセスできないので、OSSプロジェクトの場合は過去の質問や検討を追うためにログインしなければならないという状況があります。(最近は90日以上前のやりとりは隠されるという状況もあります)
メーリングリストの書庫をウェブで公開していた時代よりも情報の検索アクセス性が劣るというのは残念なので、Q&Aやリリースのお知らせなどを公開できるというのは良いと思います。
・トピックを解決済みにマークできる
https://zulip.com/help/resolve-a-topic
トピック(スレッド)に解決済みのマークを付けることができます。
Q&Aやバグ修正の対応に便利です。
またトピックにメールの件名をそのまま用いることでMLのスレッド管理代わりに用いることもできます。
この機能は応用して問い合わせ管理の業務にも使えます。
気を付けたいところ
(1)インストールはまっさらな環境で行うべし
https://zulip.readthedocs.io/en/stable/production/install.html
動作環境のページにも書かれていますが、Zulipのインストーラーはサーバー上に他のサービスが共存している事は想定していません。
https://zulip.readthedocs.io/en/stable/production/requirements.html
既存のWebとnginxで振り分けて共存..といったことは考えず、まっさらなOS環境を用意しましょう。
(2)ToDoリストは期待したとおりに並ばない
https://zulip.com/help/format-your-message-using-markdown#to-do-lists
/todo のスラッシュコマンドでToDoリストの作成入力ボックスが登場します。
便利なのですが、最初に入力した物が一番下に表示されるので、なんだか直感に反します

(3)絵文字の一括登録がたまにコケる
https://zulip.com/help/custom-emoji#bulk-add-emoji
APIから絵文字の一括登録ができるのですが大量にやると稀によくコケます。
きっと大量にやってる私が悪いのでしょう、うん
まとめ
・スレッドに名前を付けて個別に選択できる
・Home画面ですべてのチャンネルをひとつのTLとして見られる
この2点がメインですがZulipについていろいろ述べてきました。
興味を持った方は是非使ってみてください。
Zulipはいいぞ
SSVCのDecision Tableを雑に実装してみる~Twine編~
DecisionRules編からの続編です。
概要
タイトルの通りです。Twineにインポートできるhtmlファイルを置いておきます。そのまま開いて実行もできます。
https://github.com/w4yh/SSVC-decision-tree
ファイル: HarloweとSugarCubeの2種類のスタイルで作ってみました。
SSVC_Supplier_Decision_Table_Harlowe_0.0.2.html
SSVC_Supplier_Decision_Table_SugarCube_0.0.2.html
完成品
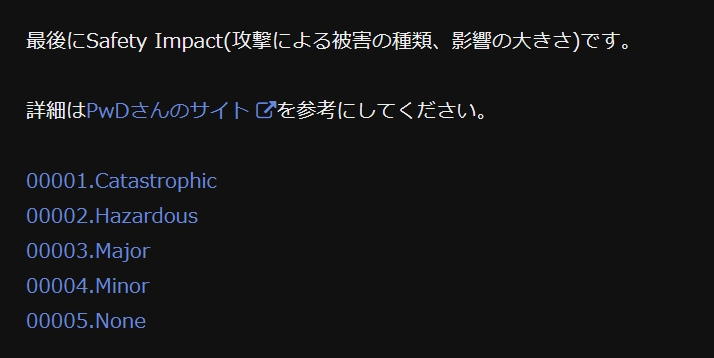
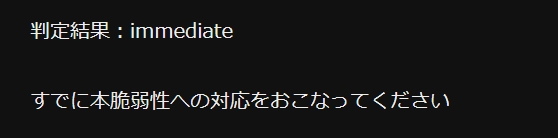
最初にデモ代わりにSugarCube版のスクリーンショットを載せておきます。
ここでは Exploitation=Active, Automatable=yes, Value Density=concentrated, Technical Impact=Total, Safety Impact=Catastrophic を選択しています。






経緯
前回はSSVCの判定をDecisionRulesで作成してみました。
一覧が見えるので分かりやすい、APIも備えているのでcURLなどCLIからも実行できるなどの利点がありました。一方でツールチップで説明文を表示するなどの機能を実装していないので、実際に使用するシーンでは別途リンクURLなどの情報が必要でした。
今回はTwineを使ってリンクURLや説明文も表示しながら実装してみました。
Twine
Twineはオープンソースのノベルゲーム作成ツールです。
私は以前からTwineで業務フローを書くという間違った使い方をしています。フローチャートやBPMNだけだと通じる相手を選んでしまうケースがあるんですよね..ドメインやサーバー証明書の購入といった事務寄りの方やサービスデスクの方などが関わる業務の説明で使ってウケたので愛用しています。
GitHub上に公開した冒頭のhtmlファイルを開くとこんな感じです。

え、色が見にくいですか?cssを編集してください。別のテーマ(SugarCube)ではこうなります。

ちょっと見やすくなりましたかね。Twine2ではデフォルトスタイルは一つ目の方(Harlowe)です。Harloweの方がノベルゲームっぽい雰囲気は出る気がしますが、お好みで選択 && css編集で色の変更 をしてください。
設計
DecisionRules編では"行を最下部に複製"を駆使して一覧にしました。今回は質問は5問しか無いですが一覧フルメッシュで作ると樹形図のようになり、枝分かれ先に同じ質問を何度も書くことになります。
そこで今回は各質問の回答をを変数に記憶しておき、最後に回答ごとの画面に遷移して判定結果を表示するという仕組みにしました。
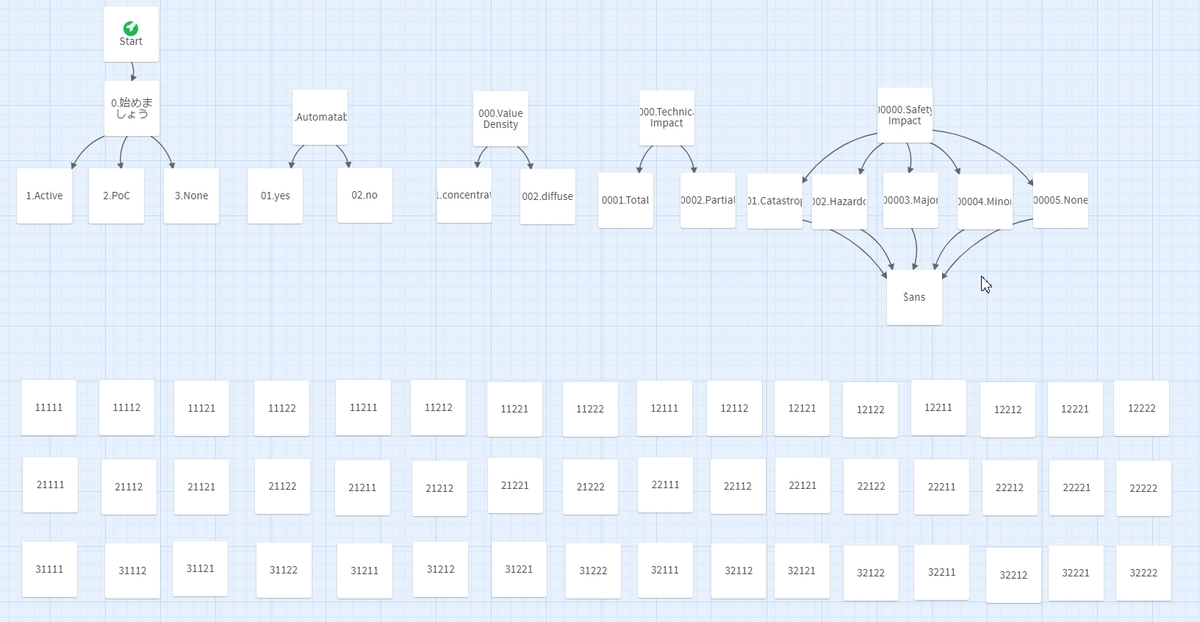
最後をif文にするか迷いましたが、判定結果を「ここはimmediateにしたい」といったカスタマイズを行う場合に長いif文よりは扱い易いかと思いこの方法にしました。SSVCの資料に合わせて左から右に縦長で配置する方が良かったかもしれません。
インポートと実行
Twine公式サイトからダウンロードしてTwineをPCにインストールしてください。
実行すると初期メニュー画面になります。右側メニューから [Import From File] を選択します。
ファイル選択画面になるので、GitHubからダウンロードしたhtmlファイルを指定します。

ファイル編集画面になります。
右下の [▶Play] を押すとデフォルトブラウザで開いて実際にプレイできます。
Twineの書き方の細かい説明は省略しますが、今回のファイルの流れだけ説明します。
設計のところでも述べましたが、各質問の答えを変数 $ans1 ~ $ans5 に記録しています。最後に連結して5桁の数字を $ans として生成し、該当の番号の選択肢(11111など)へジャンプして判定結果を表示しています。
最初のページに資料へのリンクを記載しています。独自の前提質問を追加する場合にはStartページから [0.始めましょう] の間に新しい画面(TwineではPassageと呼びます)挟むといいでしょう。Passageへのリンクは [[Passageの名前]] で表します。例えば「Javaは無いので対象外」のように「該当のパッケージがCMDB内に存在するか」といった質問を最初に加えるケースが想定されます。
振り返り
Twineで作るとディシジョンテーブル感は薄れるかもしれないですね。
しかしWiki上でパンくずリストを見ながら選択肢を大量に作るよりも扱い易いかと思います。本来ノベルゲーム用ツールなのでエンジニア向けツールというわけでもなくとっつきやすいかと思います。
5つめの質問である "Safety Impact" の判定がかなり肝な印象です。被害に関することなので、CVSSアタックベクターの中にはそのまま当てはまる項目は無いような気がします。どちらかというとISMSなどで組織毎システム毎に行ったリスク評価みたいなものがベースになるのかなと思います。リスク評価メンドクサイですが、やっぱりやらないといけませんね。。
SSVCのDecision Tableを雑に実装してみる~DecisionRules.io編~
概要
タイトルの通りです。インポート用のExcelファイルを置いておきます。
https://github.com/w4yh/SSVC-decision-tree
ファイル: SSVC_Handling_SupplierTable_0.0.2.xlsx
経緯
TwitterでSSVCのことを知りました。
📝CVSSにとって代わるかもしれない 脆弱性の管理方法 SSVC のすばらしいまとめ。CISAもSSVC推しだしhttps://t.co/VdVt6SrOKI
— Yurika (@EurekaBerry) 2022年8月10日
元となるブログ記事やその引用記事などを読んで、これはPrologで書けそうなディシジョンテーブルだなあと思いました(本投稿ではSSVC自体の説明は一切しませんので以下リンクの素晴らしいコンテンツをご参照ください)。
shinobe179.hatenablog.com
www.pwc.com
github.com
しかしPrologで書いてもProlog実行環境のインストールから説明することになるよなあ...と察したので今回はDecisionRulesというサービスを使って実装してみます。
ここではまずSSVCの"Suggested Supplier Table"を作ってみます。
DecisionRules概要
ディシジョンテーブルなどを作成&実行できる便利SaaSです。
www.decisionrules.io
Freeプランもあるのでアカウントを作成してください。ただし企業名や電話番号を求められます。
Excelからのインポートでテーブルを作成する
ログイン後、左側メニューから [Decision Tables] を選択します。
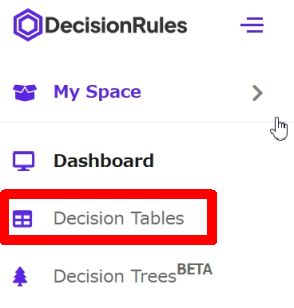
DecisionTablesのトップ画面で [+ Decision Table] を選択して新規作成していきます。
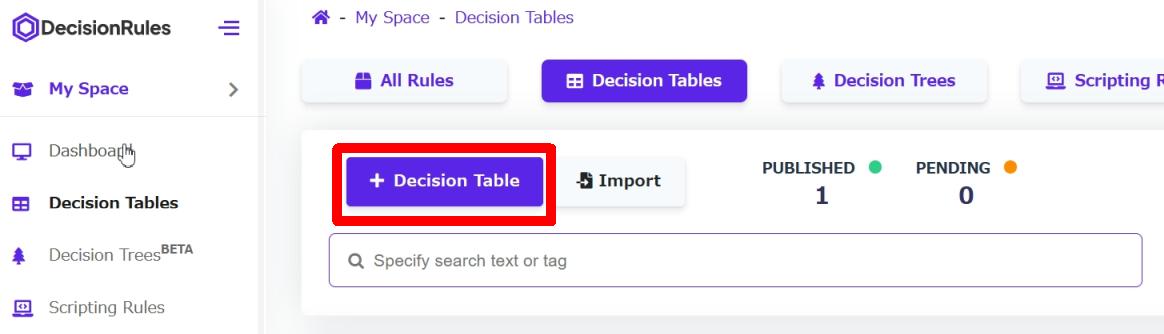
作成方法の選択画面では右の [EMPTY DECISION TABLE] を選択し、
画像の赤枠部分でこのディシジョンテーブルを命名して下の [Continue] を選択します。
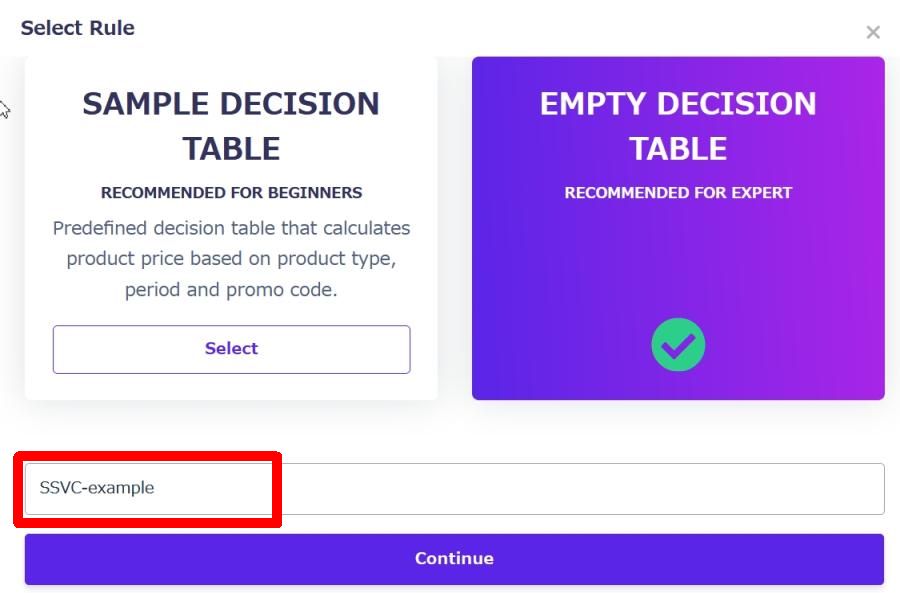
空のディシジョンテーブルが表示されます。
左側の [Rule Settings] タブに移動します。

テーブル設定画面で右上のメニューから [Import Version] を選択します。

Import Decision Table の画面に進んだら
[1. Select Version!] で [Current (version 1)] を選択し、
[2. Drop or choose file!] で本投稿先頭に示したGitHubからダウンロードしたxlsxファイルを指定します。
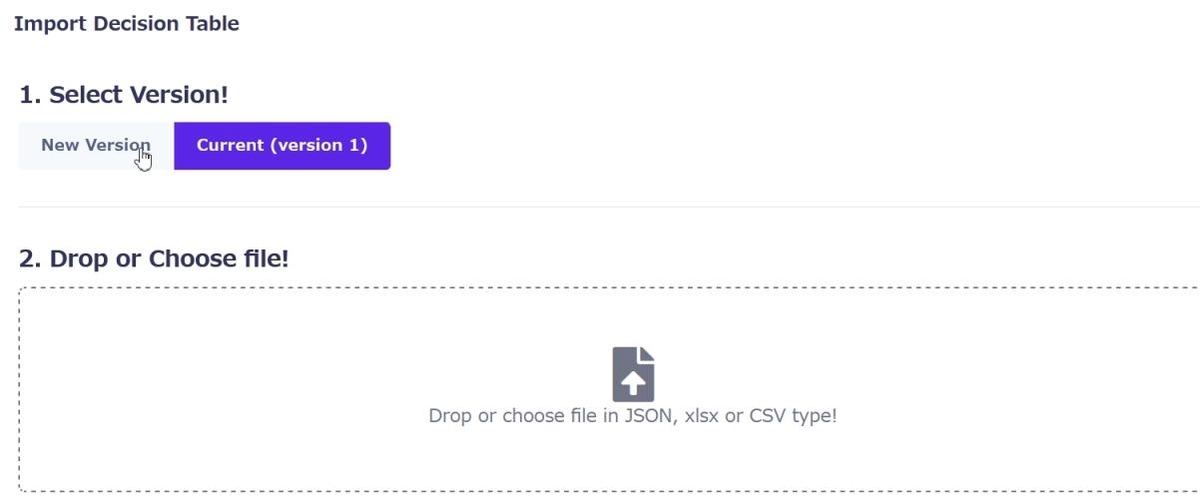
ファイルに問題が無ければ下に [Save] のボタンが表示されるので選択します。
読み込んだディシジョンテーブルが表示されます。
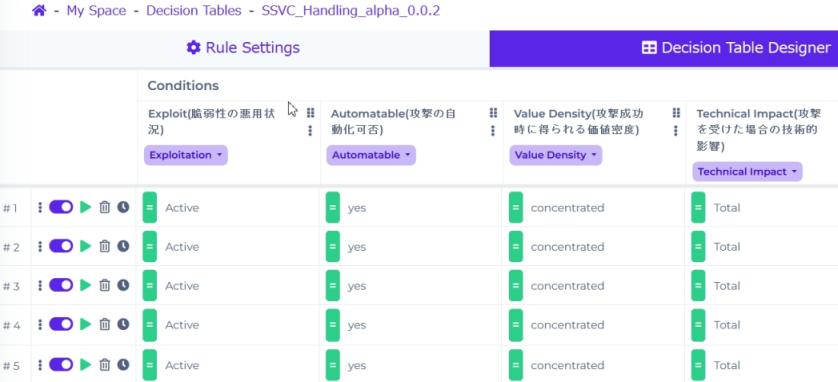
なおSSVCの項目のうちUtilityはAutomatableとValue Densityの2つから決まるので、直接AutomatableとValue Densityを入力する形にしました。さらにPublic Safety Impactは実質Safety Impactで決まるのでSafety Impactのみの入力を必要としています。
実行
テーブルを眺め終わったらさっそく実行してみましょう。
左側メニューから [Test bench] を選択します。
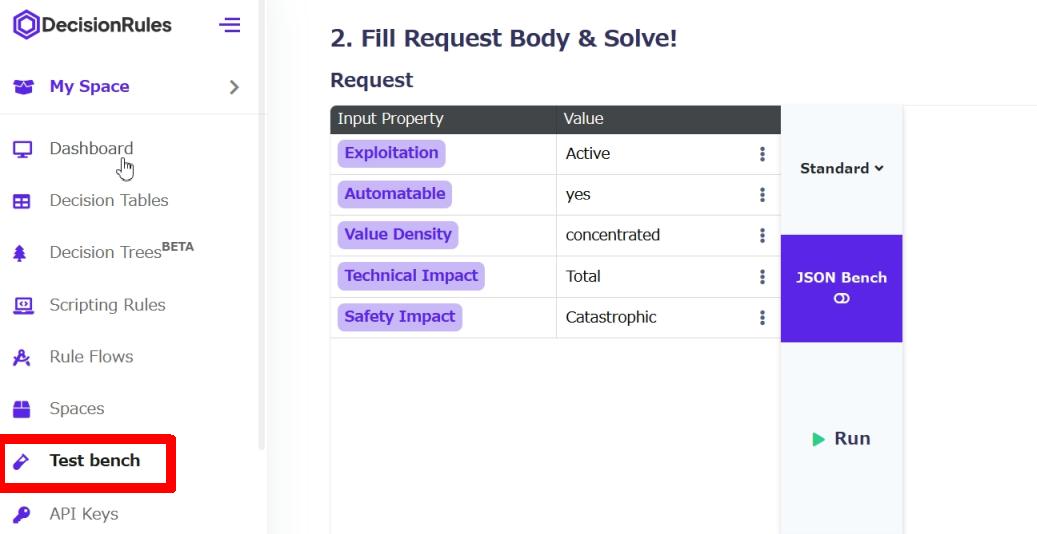
[1. Select Meta Data] の部分は自動で値が入っていると思います。
(API Key情報を含むのでキャプチャ略)
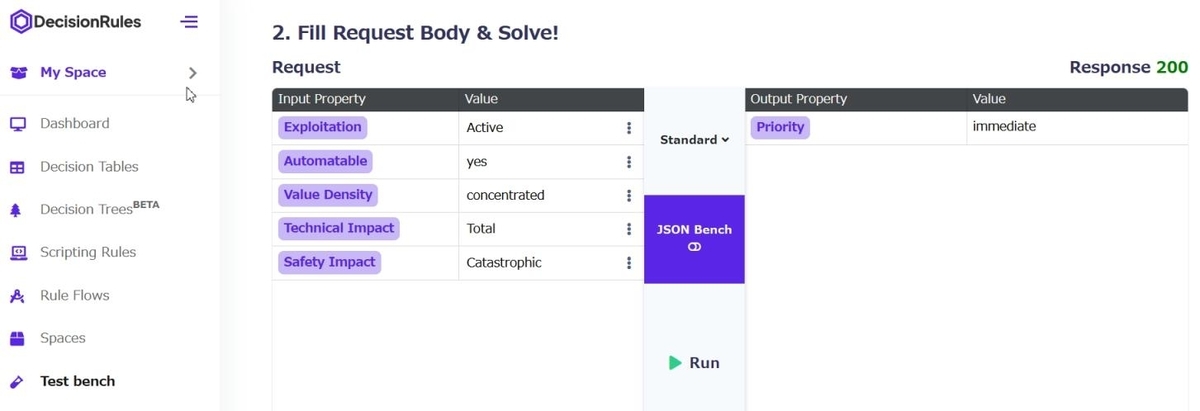
[2. Fill Request Body & Solve!] の欄に入力値を入れていきます。
Exploitation (Active | PoC | none)
Automatable (yes | no)
Value Density (concentrated | diffuse)
Technical Impact (Total | Partial)
Safety Impact (Catastrophic | Hazardous | Major | Minor | None)
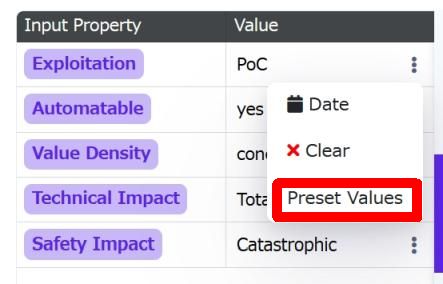
プルダウン選択..とはいきませんが、Valueの入力欄右側のハンバーガーメニュー(?縦3dots?)から [Preset Values] を選択すると値のリスト選択ダイアログが出ます。
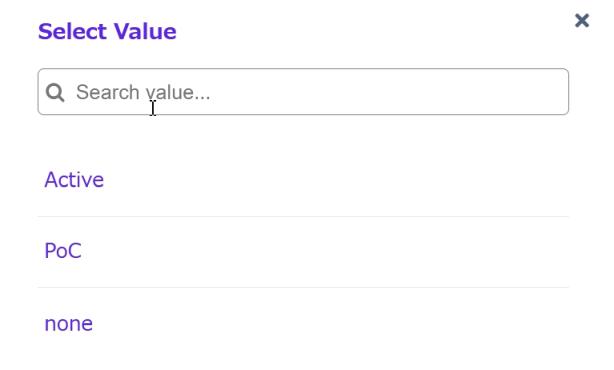
5項目の値をすべて入力して中央の [▶Run] を押します。
右側のOutputの欄に結果が表示されます。この場合は Priority=immediate、すぐに対応せよとなりました。
同じ画面の下の方に [Code example] という欄があります。ここに今行ったテストをcURLやプログラミングから実施する場合のコードが表示されます(ここもAPI Keyを含むのでキャプチャ省略)。便利ですね!

振り返り
SSVC Supplier Decision Tableの決定木をDecionRulesで実装することができました。
一覧で見通せる上Excel形式でのインポート&エクスポートもできお手軽だったと思います。
しかし、入力値のそれぞれの値についてツールチップなどで説明を表示といった機能を持たせていないので「別途資料を見ながら値の判定を行った後で最後に決定木を辿る部分だけの実装」となっています。Code Exampleの欄にPython等のコードも表示されるので周辺機能を作りこめばいいんですけどね。。でもそれならPrologでも苦労変わらないし。。
次回、「Decision TableをTwineでノベルゲームっぽく長い説明付きで実装する編」モノはできたので書けたら書きます。
エクスカーション
DecisionRules良かったです
今回たまたま見つけて使ってみましたが分かりやすかったです。コードを書けない人とビジネスルールの意識合わせをする場合にも使えそうな気がします。
また今回はインポートするので空白テーブルから作成しましたが、サンプルテーブルの内容はディシジョンテーブル界のHello Worldこと"複数の条件からなる割引率の決定"です。
IPアドレスのリストアップと集約(prips, aggregate)ついでにgrepcidr
きっかけ
@m4g さんのツイートでいろんなツールを思い出したのでまとめておきます
CIDR入れたら該当するIPアドレスが全部テキストで吐かれるツールとかないかなぁ。
— m4g (@m4quick) 2022年5月13日
192.168.0.0/16って入れたら
192.168.0.1
192.168.0.2
……
192.168.255.254
みたいに出力されるとexpingの一覧とか作る時めっちゃ楽
prips (print IP address)
私も以前同様のツールを探して、blacknonさんのブログでpripsを知りました。
ここではRPM系Linuxでのインストールと動作確認を記します。
pripsのインストール
$ git clone https://gitlab.com/prips/prips.git $ cd prips $ make $ make test prove t t/01-cidr.t ...... ok t/02-range.t ..... ok t/03-skip.t ...... ok t/04-format.t .... ok t/05-except.t .... ok t/06-cidrize.t ... ok t/07-features.t .. skipped: The feature-check tool does not seem to be present All tests successful. Files=7, Tests=74, 1 wallclock secs ( 0.06 usr 0.02 sys + 0.34 cusr 0.12 csys = 0.54 CPU) Result: PASS $ sudo make install $ hash -r
pripsの使用例
まずはヘルプを見てみます。
$ prips -h usage: prips [options] <start end | CIDR block> -c print range in CIDR notation -d <x> set the delimiter to the character with ASCII code 'x' where 0 <= x <= 255 -h display this help message and exit -f <x> set the format of addresses (hex, dec, or dot) -i <x> set the increment to 'x' -e <x.x.x,x.x> exclude a range from the output, e.g. -e ..4. will not print 192.168.4.[0-255] prips --help | --version | --features Report bugs to Peter Pentchev <roam@ringlet.net>
元々のお題をであるCIDRを入れたらレンジ内のIPアドレスを列挙する、をやってみます。
prips 203.0.113.0/29 203.0.113.0 203.0.113.1 203.0.113.2 203.0.113.3 203.0.113.4 203.0.113.5 203.0.113.6 203.0.113.7
残念ながらCIDR表記指定などのオプションは無いので、末尾に/32を付けたい場合はsedします。
$ prips 203.0.113.0/29 | sed -e 's/$/\/32/g' 203.0.113.0/32 203.0.113.1/32 203.0.113.2/32 203.0.113.3/32 203.0.113.4/32 203.0.113.5/32 203.0.113.6/32 203.0.113.7/32
aggregate
ついでに関連ツールも書いていきます。
aggregateはその名の通りCIDR表記のアドレスリストを集約するツールです。
aggregateのインストール
epelにパッケージがあるのでyumで導入できます。
yum install aggregate そっち系の方は yum install aggregate-ios も便利かもしれません。
ソースコードからコンパイルしたい方はこちらから。
みんな大好きBIND DNSサーバーのISCさんのサーバーから入手できます。
https://ftp.isc.org/isc/aggregate/
grepcidr
grepcidrはCIDR表記のレンジやIPアドレスについて包含関係を判定するコマンドです。
当時yunazunoさんのブログで知りました。
yunazuno.hatenablog.com
grepcidrのインストール
atomic repoを用いてyumでインストールできます。
# curl -s https://updates.atomicorp.com/installers/atomic | sh # yum --enablerepo=atomic install grepcidr =================================================================================================================================== Package アーキテクチャー バージョン リポジトリー 容量 =================================================================================================================================== インストール中: grepcidr x86_64 2.0-1.el7.art atomic 21 k トランザクションの要約 =================================================================================================================================== インストール 1 パッケージ
sort
IPアドレスのソートは以下のsortコマンドオプションが使えます。
sort -n -t '.' -k 1,1 -k 2,2 -k 3,3 -k 4,4
$ cat sampleIPaddress.list 203.0.113.64 192.0.2.12 198.51.100.230 192.0.2.1 $ cat sampleIPaddress.list | sort -n -t '.' -k 1,1 -k 2,2 -k 3,3 -k 4,4 192.0.2.1 192.0.2.12 198.51.100.230 203.0.113.64
/32表記でも同じ結果が得られます。
$ cat sampleIPaddress.list 203.0.113.64/32 192.0.2.12/32 198.51.100.230/32 192.0.2.1/32 $ sort -n -t '.' -k 1,1 -k 2,2 -k 3,3 -k 4,4 sampleIPaddress.list 192.0.2.1/32 192.0.2.12/32 198.51.100.230/32 203.0.113.64/32
まとめ
IPアドレスやCIDRは小数でもない直接扱いにくい形式ですが、先人のみなさまが便利ツールを提供してくださっているので便利にシュッと使っていきたいですね。